See fallthrough below.BooleantrueimmutableEnable or disable the immutable directive in the Cache-Control response header. If enabled, the maxAge option should also be specified to enable caching. You can configure multiple properties with different lengths in a single configuration.

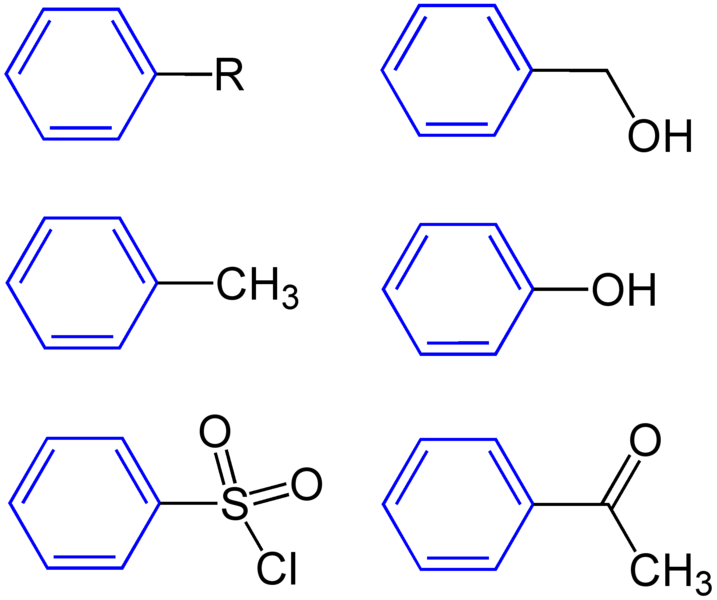
Fully-qualified names for columns are of the form databaseName.tableName.columnName. ReLU ReLU Activation An Activation layer performing ReLU followed by an activation performing ReLU will be replaced by a single activation layer. Convolution and ReLU Activation The Convolution layer can be of any type and there are no restrictions on values. Convolution and GELU Activation The precision of input and output should be the same; with both of them FP16 or INT8. TensorRT should be running on a Turing or later device with CUDA version 10.0 or later. Convolution and Clip Activation The Convolution layer can be any type and there are no restrictions on values.

Scale and Activation The Scale layer followed by an Activation layer can be fused into a single Activation layer. Convolution And ElementWise Operation A Convolution layer followed by a simple sum, min, or max in an ElementWise layer can be fused into the Convolution layer. The sum must not use broadcasting, unless the broadcasting is across the batch size. Shuffle and Reduce A Shuffle layer without reshape, followed by a Reduce layer can be fused into a single Reduce layer.

The Shuffle layer can perform permutations but cannot perform any reshape operation. The Reduce layer must have a keepDimensions set of dimensions. Shuffle and Shuffle Each Shuffle layer consists of a transpose, a reshape, and a second transpose.
A Shuffle layer followed by another Shuffle layer can be replaced by a single Shuffle . If both Shuffle layers perform reshape operations, this fusion is only allowed if the second transpose of the first shuffle is the inverse of the first transpose of the second shuffle. Scale A Scale layer that adds 0, multiplied by 1, or computes powers to the 1 can be erased. Convolution and Scale A Convolution layer followed by a Scale layer that is kUNIFORM or kCHANNEL can be fused into a single convolution by adjusting the convolution weights. This fusion is disabled if the scale has a non-constant powerparameter. Reduce A Reduce layer that performs average pooling will be replaced by a Pooling layer.

The Reduce layer must have a keepDimensions set, reduced across H and W dimensions from CHW input format before batching, using the kAVG operation. Convolution and Pooling The Convolution and Pooling layers must have the same precision. The Convolution layer may already have a fused activation operation from a previous fusion. Depthwise Separable Convolution A depthwise convolution with activation followed by a convolution with activation may sometimes be fused into a single optimized DepSepConvolution layer. The precision of both convolutions must be INT8 and the device's computes capability must be 7.2 or later.

SoftMax and Log It can be fused into a single Softmax layer if the SoftMax has not already been fused with a previous log operation. SoftMax and TopK Can be fused into a single layer. The SoftMax may or may not include a Log operation. FullyConnected The FullyConnected layer will be converted into the Convolution layer, all fusions for convolution will take effect.
Determines if the result of authentication via the LDAP server should be cached or not. Caching is used to limit the number of LDAP requests that have to be made over the network for users that have already been authenticated successfully. A user can be authenticated against an existing cache entry as long as it is alive (see dbms.security.auth_cache_ttl). An important consequence of setting this to true is that Neo4j then needs to cache a hashed version of the credentials in order to perform credentials matching.

This hashing is done using a cryptographic hash function together with a random salt. Preferably a conscious decision should be made if this method is considered acceptable by the security standards of the organization in which this Neo4j instance is deployed. Most layers support broadcasting across the batch dimension to avoid copying data unnecessarily, but this will be disabled if the output is concatenated with other tensors. Gather Layer To get the maximum performance out of a Gather layer, use an axis of 0. There are no fusions available for a Gather layer. Reduce Layer To get the maximum performance out of a Reduce layer, perform the reduction across the last dimensions .
This allows optimal memory to read/write patterns through sequential memory locations. If doing common reduction operations, express the reduction in a way that will be fused to a single operation if possible. RNN Layer If possible, opt to use the newer RNNv2 interface in preference to the legacy RNN interface.

The newer interface supports variable sequence lengths and variable batch sizes, as well as having a more consistent interface. To get maximum performance, larger batch sizes are better. In general, sizes that are multiples of 64 achieve highest performance. Bidirectional RNN-mode prevents wavefront propagation because of the added dependency, therefore, it tends to be slower. 'file' - the incoming payload is written to temporary file in the directory specified by theuploads settings.

If the payload is 'multipart/form-data' andparse is true, field values are presented as text while files are saved to disk. Note that it is the sole responsibility of the application to clean up the files generated by the framework. This can be done by keeping track of which files are used (e.g. using the request.app object), and listening to the server 'response' event to perform cleanup. Again, by default, the code contained in the method must not block.3The method gets a RoutingContext as a parameter. Once you have a network definition and a builder configuration, you can call the builder to create the engine. The builder eliminates dead computations, folds constants, and reorders and combines operations to run more efficiently on the GPU.

100GB of each NVMe is reserved for NFS cache to help speed access to common libraries. When calculating maximum usable storage size, this cache and formatting overhead should be considered; We recommend a maximum storage of 1.4TB (6TB for high-memory nodes). The NVMes could be used to reduce the time that applications wait for I/O. Using an SSD drive per compute node, the burst buffer will be used to transfer data to or from the drive before the application reads a file or after it writes a file.

The result will be that the application benefits from native SSD performance for a portion of its I/O requests. Data can also be written directly to the parallel filesystem. Because Cursor objects always operate in context of single Connection ,Cursor instances are not created directly, but by constructor method.
However, Firebird supports multiple independent transactions per connection. To conform to Python DB API, FDB uses concept of internal main_transactionand secondary transactions. Cursor constructor is primarily defined byTransaction, and Cursor constructor on Connection is therefore a shortcut for main_transaction.cursor().

Hash_policy(repeated config.route.v3.RouteAction.HashPolicy) Specifies a list of hash policies to use for ring hash load balancing. Each hash policy is evaluated individually and the combined result is used to route the request. The method of combination is deterministic such that identical lists of hash policies will produce the same hash. Since a hash policy examines specific parts of a request, it can fail to produce a hash (i.e. if the hashed header is not present).
If all configured hash policies fail to generate a hash, no hash will be produced for the route. In this case, the behavior is the same as if no hash policies were specified (i.e. the ring hash load balancer will choose a random backend). If a hash policy has the "terminal" attribute set to true, and there is already a hash generated, the hash is returned immediately, ignoring the rest of the hash policy list. This userdata must start with the structure luaL_Stream; it can contain other data after this initial structure.

Once Lua calls this field, it changes the field value to NULLto signal that the handle is closed. Since the C and D matrices may be 32-bit, the output may have a higher degree of precision than the input. 'stream' - the incoming payload is made available via a Stream.Readable interface. If the payload is 'multipart/form-data' and parse is true, field values are presented as text while files are provided as streams.

File streams from a 'multipart/form-data' upload will also have a hapi property containing the filename andheaders properties. Note that payload streams for multipart payloads are a synthetic interface created on top of the entire multipart content loaded into memory. To avoid loading large multipart payloads into memory, set parse to false and handle the multipart payload in the handler using a streaming parser (e.g. pez). Ifmethodis set to "via-file", OpenVPN will write the username and password to the first two lines of a temporary file. The filename will be passed as an argument toscript,and the file will be automatically deleted by OpenVPN after the script returns. The location of the temporary file is controlled by the--tmp-diroption, and will default to the current directory if unspecified.
For security, consider setting--tmp-dirto a volatile storage medium such as/dev/shm to prevent the username/password file from touching the hard drive. It has a doIteration method that will get the children it should iterate over and then call visit on each element. Per default this will call visit which then iterates over the children of this child.Visitable has also changed to ensure that any node will be able to return children .
But visit will call visit if it is of type NodeType1. In fact, we don't need the doIteration method, we could do that in visit too, but this variant has some benefits. It allows us to write a new Visitor that overwrites visit for error cases which of course means we must not do super.visit but doIteration.

The zuul.routes entries actually bind to an object of type ZuulProperties. If you look at the properties of that object, you can see that it also has a retryable flag. Set that flag to true to have the Ribbon client automatically retry failed requests. You can also set that flag to true when you need to modify the parameters of the retry operations that use the Ribbon client configuration.
Renamed configuration optionvisitTimeout to pageLoadTimeout. If you were specifically setting visitTimeout in your cypress.json file it will be transparently rewritten pageLoadTimeout on the next server boot. This option was renamed because now multiple commands cy.visit(), cy.go(), andcy.reload() all depend on this timeout option.
The ONNX parser automatically attempts to import unrecognized nodes as plugins. By default, the parser uses "1" as the plugin version and "" as the plugin namespace. This behavior can be overridden by setting a plugin_versionand/or plugin_namespace string attribute in the corresponding ONNX node.

Calls function f with the given arguments in protected mode. This means that any error insidef is not propagated; instead, pcall catches the error and returns a status code. Its first result is the status code , which is true if the call succeeds without errors. In such case, pcall also returns all results from the call, after this first result. In case of any error, pcall returns false plus the error message. You can pre-configure the GitLab Docker image by adding the environment variableGITLAB_OMNIBUS_CONFIG to Docker run command.
This variable can contain anygitlab.rb setting and is evaluated before the loading of the container'sgitlab.rb file. This behavior allows you to configure the external GitLab URL, and make database configuration or any other option from theOmnibus GitLab template. The settings contained in GITLAB_OMNIBUS_CONFIG aren't written to thegitlab.rb configuration file, and are evaluated on load. Flags - when caching is enabled, an object used to set optional method result flags. This parameter is provided automatically and can only be accessed/modified within the method function. It cannot be passed as an argument.ttl - 0 if result is valid but cannot be cached.

Tags - a string or an array of strings (e.g. ['error', 'database', 'read']) used to identify the event. Tags are used instead of log levels and provide a much more expressive mechanism for describing and filtering events. Any logs generated by the server internally include the 'hapi' tag along with event-specific information. Arguments on the commandline are by nature Strings but can be converted to richer types automatically by supplying additional typing information. For the annotation-based argument definition style, these types are supplied using the field types for annotation properties or return types of annotated methods .

For the dynamic method style of argument definition a special 'type' property is supported which allows you to specify a Class name. The @Builder AST transformation is used to help write classes that can be created using fluent api calls. The transform supports multiple building strategies to cover a range of cases and there are a number of configuration options to customize the building process. If you're an AST hacker, you can also define your own strategy class. The following table lists the available strategies that are bundled with Groovy and the configuration options each strategy supports.

In Java, this code will output Nope, because method selection is done at compile time and based on the declared types. So even if o is a String at runtime, it is still the Object version which is called, because o has been declared as an Object. To be short, in Java, declared types are most important, be it variable types, parameter types or return types. The direct path load engine uses the column array structure to format Oracle data blocks and build index keys.
The newly formatted database blocks are written directly to the database (multiple blocks per I/O request using asynchronous writes if the host platform supports asynchronous I/O). An optional, comma-separated list of regular expressions that match the fully-qualified names of columns to include in change event record values. An optional, comma-separated list of regular expressions that match the fully-qualified names of columns to exclude from change event record values. An optional, comma-separated list of regular expressions that match fully-qualified table identifiers of tables whose changes you want to capture. The connector does not capture changes in any table not included in table.include.list. Each identifier is of the form databaseName.tableName.